Machine Learning Project: Fraud Detection with Credit Cards Dataset
About
This dataset is obtained from kaggle Credit Cards Fraud Detection dataset that can be found here: https://www.kaggle.com/mlg-ulb/creditcardfraud
Content
The datasets contains transactions made by credit cards in September 2013 by european cardholders. This dataset presents transactions that occurred in two days, where we have 492 frauds out of 284,807 transactions. The dataset is highly unbalanced, the positive class (frauds) account for 0.172% of all transactions.
It contains only numerical input variables which are the result of a PCA transformation. Unfortunately, due to confidentiality issues, we cannot provide the original features and more background information about the data. Features V1, V2, … V28 are the principal components obtained with PCA, the only features which have not been transformed with PCA are ‘Time’ and ‘Amount’. Feature ‘Time’ contains the seconds elapsed between each transaction and the first transaction in the dataset. The feature ‘Amount’ is the transaction Amount, this feature can be used for example-dependant cost-senstive learning. Feature ‘Class’ is the response variable and it takes value 1 in case of fraud and 0 otherwise.
Importing the libraries
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split,cross_val_predict,cross_val_score
from sklearn.metrics import confusion_matrix,accuracy_score,roc_curve,auc,classification_report,roc_auc_score
#from scikitplot.metrics import plot_confusion_matrix,plot_precision_recall_curve
import lightgbm as lgb
from sklearn.model_selection import StratifiedKFold
Lets read the data and see what it is.
df = pd.read_csv("creditcard.csv")
df.head()
#count for target classes
fig, ax = plt.subplots(figsize = (20,5))
sns.countplot(df.Class.values,palette='husl')

#Percentage of target classes count
df['Class'].value_counts(normalize=True)
We can observed that 99.8% of data is non fraud credit card transaction and 0.17% of data is fraud transaction. Dataset is highly imbalanced.
#Distribution of attributes
attributes=df.columns.values[1:30]
def plot_attribute_distribution(attributes):
i=0
sns.set_style('whitegrid')
fig=plt.figure()
ax=plt.subplots(5,6,figsize=(22,18))
for var in attributes:
i+=1
plt.subplot(5,6,i)
sns.distplot(df[var],hist=False)
plt.xlabel('var',)
sns.set_style("ticks", {"xtick.major.size": 8, "ytick.major.size": 8})
plt.show()
plot_attribute_distribution(attributes)
#Correlations in training attributes
attributes=df.columns.values[1:30]
correlations=df[attributes].corr().abs().unstack().sort_values(kind='quicksort').reset_index()
correlations=correlations[correlations['level_0']!=correlations['level_1']]
print(correlations)
Correlations between the attributes are very small.
#normalized the amount variable by using standard scaler
ss=StandardScaler()
#convert to numpy array
amount=np.array(df['Amount']).reshape(-1,1)
#fit transform the data
amount_ss=ss.fit_transform(amount)
#Create a dataframe
amount_df=pd.DataFrame(amount_ss,columns=['Amount'])
amount_df.head()
Amount
-0 0.244964
-1 -0.342475
-2 1.160686
-3 0.140534
-4 -0.073403
#Creating the amount variable
df['Amount']=amount_df
df.head()
#Training data
X=df.drop(['Time','Class'],axis=1)
Y=df['Class']
X_train,X_test,y_train,y_test=train_test_split(X,Y,test_size=0.25)
print('Shape of X_train :',X_train.shape)
print('Shape of X_test:',X_test.shape)
print('Shape of y_train :',y_test.shape)
print('Shape of y_test :',y_test.shape)
Shape of X_train : (213605, 29) Shape of X_test: (71202, 29) Shape of y_train : (71202,) Shape of y_test : (71202,)
x=X_train
y=y_train
#StratifiedKFold cross validator
cv=StratifiedKFold(n_splits=5,random_state=42)
for train_index,valid_index in cv.split(x,y):
X_t, X_v=x.iloc[train_index], x.iloc[valid_index]
y_t, y_v=y.iloc[train_index], y.iloc[valid_index]
print('Shape of X_train :',X_t.shape)
print('Shape of X_test:',X_v.shape)
print('Shape of y_train :',y_t.shape)
print('Shape of y_test :',y_v.shape)
Shape of X_train : (170885, 29) Shape of X_test: (42720, 29) Shape of y_train : (170885,) Shape of y_test : (42720,)
#Training the lgbm model
#train data
lgb_train=lgb.Dataset(X_t,y_t)
#validation data
lgb_valid=lgb.Dataset(X_v,y_v)
#choosing the hyperparameters
params={'boosting_type': 'gbdt',
'max_depth' : 25,
'objective': 'binary',
'boost_from_average':False,
'nthread': 12,
'num_leaves': 120,
'learning_rate': 0.07,
'max_bin': 1000,
'subsample_for_bin': 200,
'is_unbalance':True,
'metric' : 'auc',
}
#training the model
num_round=5000
lgbm= lgb.train(params,lgb_train,num_round,valid_sets=[lgb_train,lgb_valid],verbose_eval=500,early_stopping_rounds = 4000)
-Training until validation scores don’t improve for 4000 rounds.
-[500] training’s auc: 1 valid_1’s auc: 0.980957
-[1000] training’s auc: 1 valid_1’s auc: 0.983403
-[1500] training’s auc: 1 valid_1’s auc: 0.983669
-[2000] training’s auc: 1 valid_1’s auc: 0.983301
-[2500] training’s auc: 1 valid_1’s auc: 0.982314
-[3000] training’s auc: 1 valid_1’s auc: 0.982706
-[3500] training’s auc: 1 valid_1’s auc: 0.983112
-[4000] training’s auc: 1 valid_1’s auc: 0.983454
-Early stopping, best iteration is:
-[108] training’s auc: 1 valid_1’s auc: 0.940468
#Model performance on test data
#predict the model
lgbm_predict_prob=lgbm.predict(X_test,random_state=42,num_iteration=lgbm.best_iteration)
print(lgbm_predict_prob)
#Convert to binary output
lgbm_predict=np.where(lgbm_predict_prob>=0.5,1,0)
print(lgbm_predict)
lgb.plot_importance(lgbm,max_num_features=29,importance_type="split",figsize=(15,8))

plt.figure()
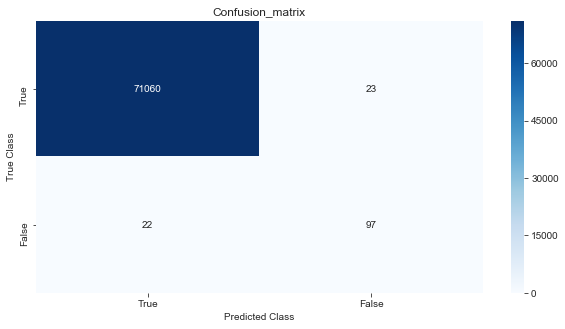
#confusion matrix
cm=confusion_matrix(y_test,lgbm_predict)
print(cm)
labels=['True','False']
plt.figure(figsize=(10,5))
sns.heatmap(cm,xticklabels=labels,yticklabels=labels,cmap='Blues',vmin=0.2,annot=True,fmt='d')
plt.title('Confusion_matrix')
plt.xlabel('Predicted Class')
plt.ylabel('True Class')
plt.show()
#printing the classification report
print(classification_report(y_test,lgbm_predict))